SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer Based on Source-Filter Model
SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer Based on Source-Filter Model
Abstract
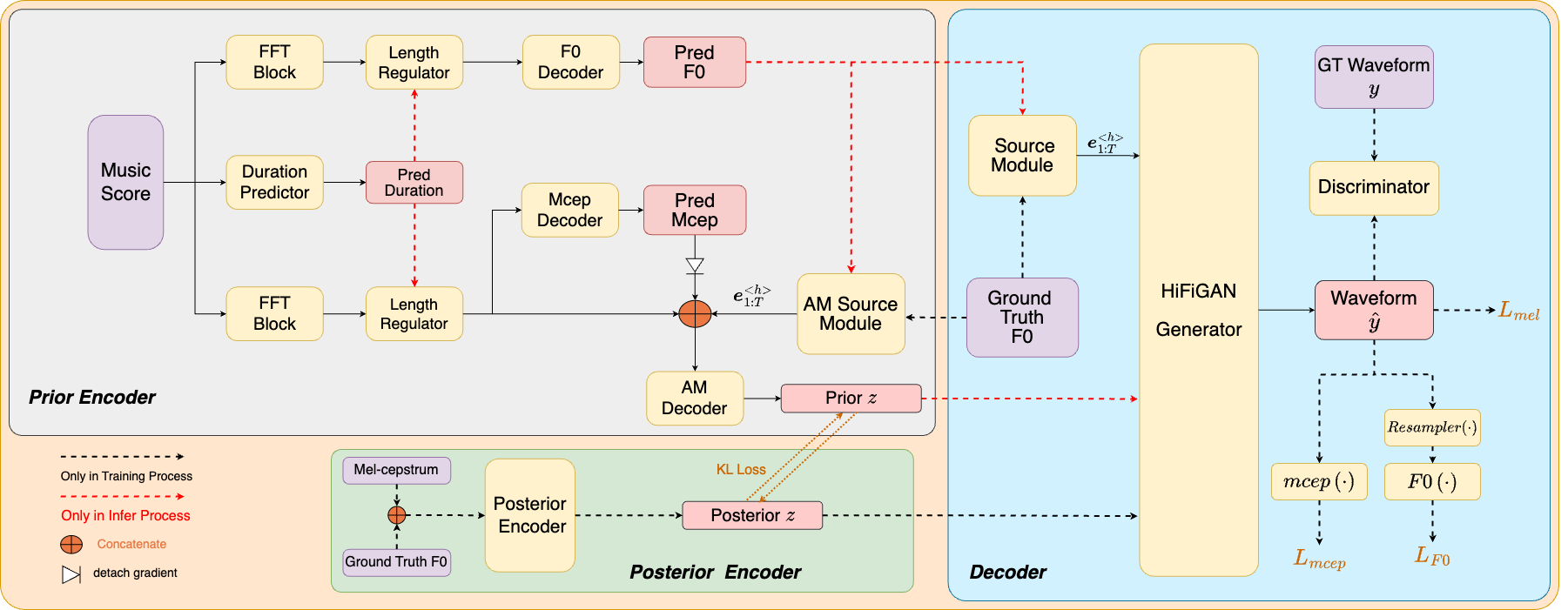
This paper presents an advanced end-to-end singing voice synthesis (SVS) system combining the source-filter mechanism which directly translates lyrical and melodic cues into expressive and high-fidelity human-like singing. Similar with other systems such as VISinger2, the proposed system also utilizes training paradigms evolved from VITS and incorporates elements like the fundamental pitch (F0) predictor and waveform generation decoder. To address a critical challenge that the coupling of mel-spectrogram features with F0 information that may introduce additional errors during F0 prediction, two primary solutions are proposed in this paper. Firstly, we leverage mel-cepstrum (mcep) features to decouple the intertwined mel-spectrogram and F0 characteristics. Secondly, inspired by the neural source-filter models, we introduce source excitation signals as the representation of F0 in SVS system, aiming to capture pitch nuances more accurately. Meanwhile differentiable mcep and F0 losses are employed as the waveform decoder supervision to fortify the prediction accuracy of speech envelope and pitch in generated speech.Extensive experiments on the Opencpop dataset demonstrate that our proposed model surpasses VISinger2 predecessor in synthesis quality and intonation accuracy.
(We apologize for an oversight in the camera-ready version of our paper. A minor error occurred in Fig. 1 of the document, where the position of the gradient cutoff symbol was incorrect. This has now been corrected in the figure displayed on this webpage.)