DurIAN-E: Duration Informed Attention Network For Expressive Text-to-Speech Synthesis
DurIAN-E: Duration Informed Attention Network For Expressive Text-to-Speech Synthesis
Abstract
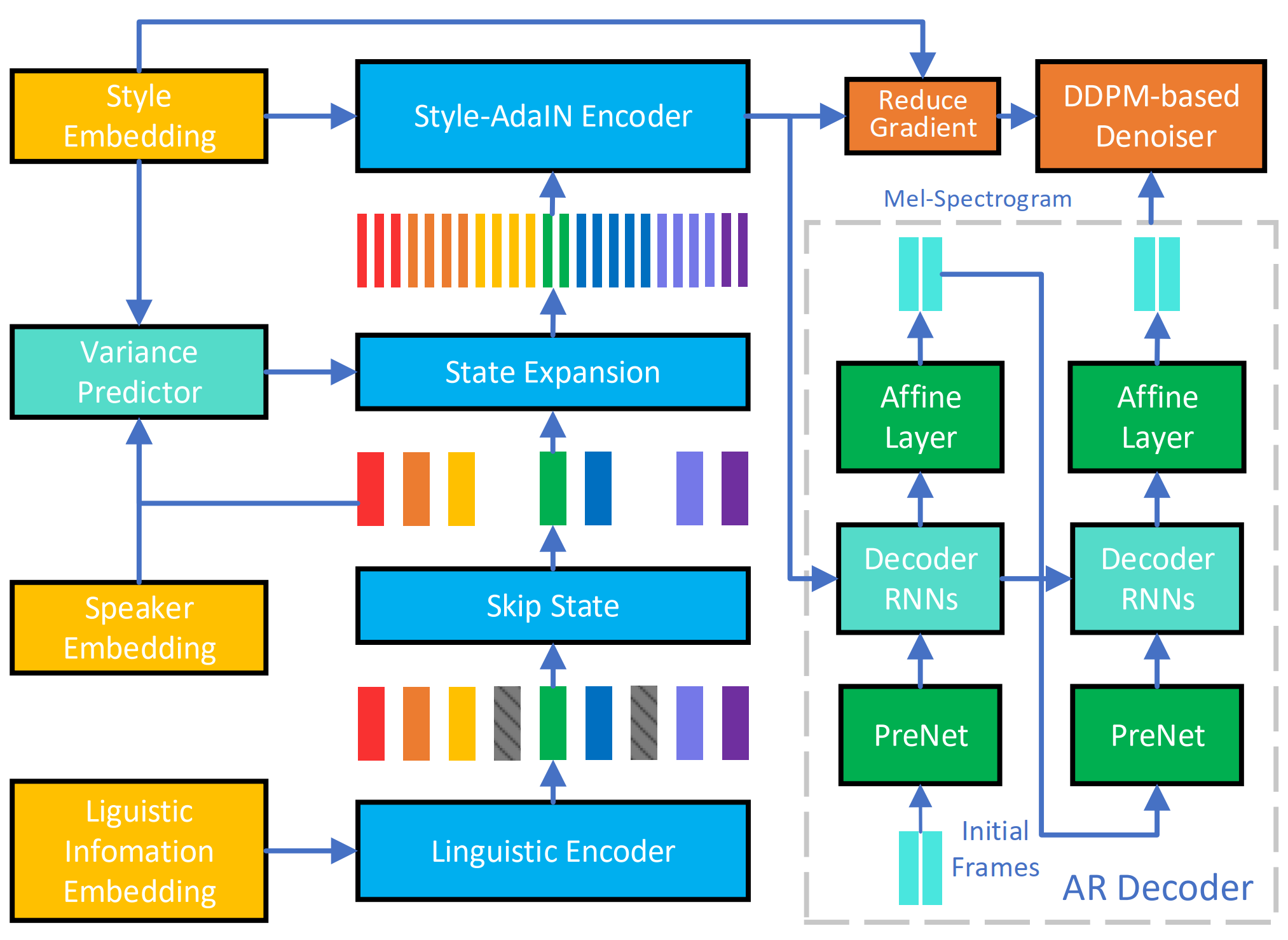
This paper introduces an improved duration informed attention neural network (DurIAN-E) for expressive and high-fidelity text-to-speech (TTS) synthesis. Inherited from the original DurIAN model, an auto-regressive model structure in which the alignments between the input linguistic information and the output acoustic features are inferred from a duration model is adopted. Meanwhile the proposed DurIAN-E utilizes multiple stacked SwishRNN-based Transformer blocks as linguistic encoders.
Style-Adaptive Instance Normalization (SAIN) layers are exploited into
frame-level encoders to improve the modeling ability of expressiveness.
A denoiser incorporating both denoising diffusion probabilistic model (DDPM) for mel-spectrograms and SAIN modules is conducted to further improve the synthetic speech quality and expressiveness.
Experimental results prove that the proposed expressive TTS model in this paper can achieve better performance than the state-of-the-art approaches in both subjective mean opinion score (MOS) and preference tests.
Sound Samples
* Note: All samples are in Mandrin Chinese.
synthesized demos from different systems
System
Demo1
Demo2
GT (vocoder)
FastSpeech 2
DurIAN
DiffSpeech
DurIAN-E
System
Demo3
Demo4
GT (vocoder)
FastSpeech 2
DurIAN
DiffSpeech
DurIAN-E
System
Demo5
Demo6
GT (vocoder)
FastSpeech 2
DurIAN
DiffSpeech
DurIAN-E
System
Demo7
Demo8
GT (vocoder)
FastSpeech 2
DurIAN
DiffSpeech
DurIAN-E
System
Demo9
Demo10
GT (vocoder)
FastSpeech 2
DurIAN
DiffSpeech
DurIAN-E
Ablation test demos
system description
DurIAN-E: The proposed system
DurIAN-E-postnet: The model using post-net in Tacotron2 as the denoiser instead of DDPM
DurIAN-E-ffn: Using standard Transformers as the linguistic encoder instead of SwishRNN-based ones